Zengzhi Wang | Shanghai Jiao Tong University
Shanghai Jiao Tong University. (zengzhi.wang [at] sjtu dot edu dot cn).

We should dream big.
Hi, there! I am Zengzhi Wang (王增志), a first-year PhD student at GAIR Lab, Shanghai Jiao Tong University, advised by Prof. Pengfei Liu. Before that, I received my master’s degree in Computer Science at the Nanjing University of Science & Technology advised by Prof. Rui Xia and Assoc. Prof. Jianfei Yu. I obtained my bachelor’s degree in Software Engineering at Wuhan Institute of Technology.
I curated data and trained models — and in turn, data, models, and results also trained me. My recent work mainly focuses on the following three aspects:
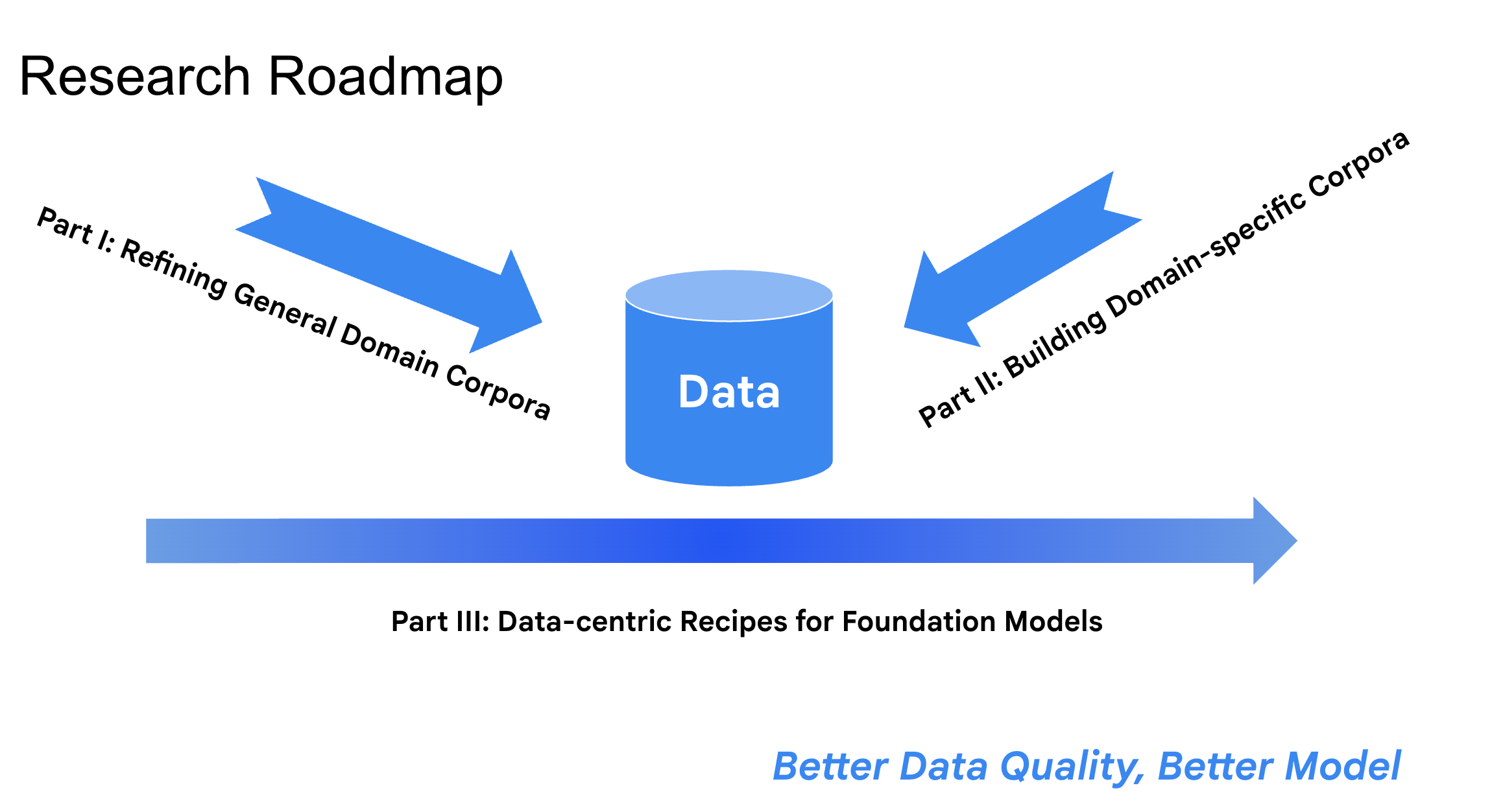
- Building Domain-Specific (e.g., math) Corpora: Creator of MathPile (9.5B tokens, NeurIPS 2024) and MegaMath (> 370B tokens, COLM 2025), large-scale math-focused datasets designed to advance mathematical reasoning in language models.
- General Pre-training Corpora Refinement: Co-creator of ProX(ICML 2025), a scalable framework that leverages tiny language models to automatically refine large-scale corpora, along with refined byproducts, such as FineWeb-Pro (100B tokens) and DCLM-Pro (>500B tokens). Check Huggingface for more releases.
- Data-centric Recipes for Building Foundation Models: Initiator of OctoThinker, unveiling the principles behind RL-friendly base language models and lifting foundation model capabilities through large-scale mid-training.
Now, I’m scaling both the quality and quantity of data while advancing the scientific understanding of foundation models. 😄
news
| Jul 09, 2025 | 💎 MegaMath accpeted to COLM 2025 🐙 OctoThinker accpeted to the AI4Math Workshop @ ICML 2025! |
|---|---|
| May 01, 2025 | One paper (🫐 ProX) accepted by ICML’25. |
| Apr 29, 2025 | Say hi to 🐙 OctoThinker - our new mid-training efforts for building strong reasoning base models tailored for the RL scaling era. |
| Apr 09, 2025 | PhDing @ SJTU (just started). |
| Apr 08, 2025 | Introduce 💎 MegaMath, the largest open-source math pre-training data to date containing 💥370B 💥tokens of web, code, and synthetic data! |
selected publications
- ICML 2025Programming Every Example: Lifting Pre-training Data Quality like Experts at ScaleIn International Conference on Machine Learning, 2025
- AI4Math@ICML 2025OctoThinker: Revisiting Mid-Training In the Era of RL ScalingIn 2nd AI for Math Workshop @ ICML, 2025